Optimizing AI Microservices: Reducing Docker Image Sizes for Production
The Challenge: Addressing Container Bloat
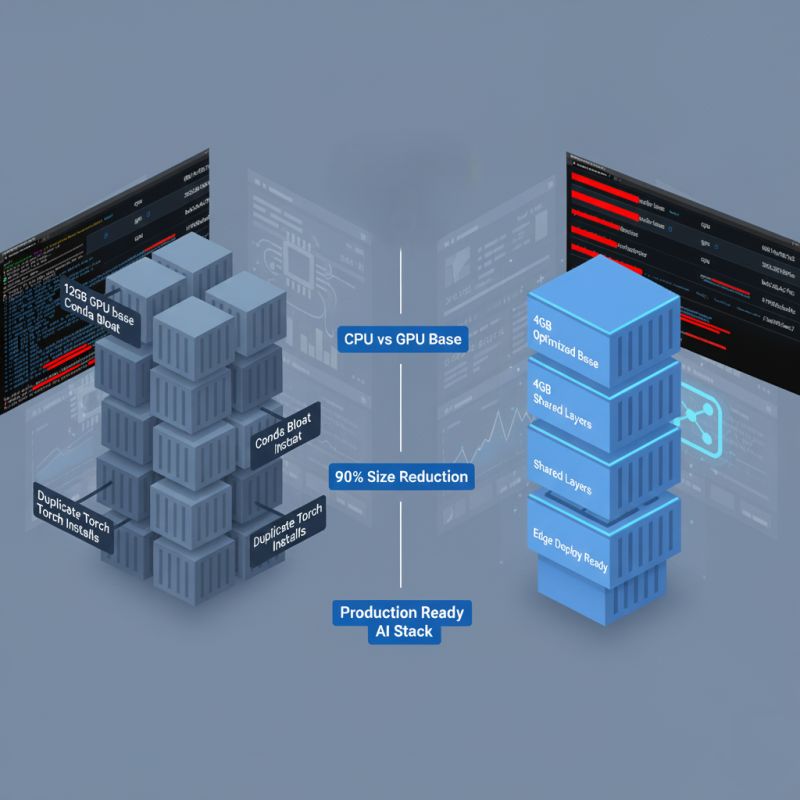
Moving an AI system from a demonstration environment to production requires a fundamental shift in infrastructure strategy. During a recent deployment of a multi-microservice AI system, it became clear that standard configurations often lead to unsustainable container bloat. Initial images for the eight-service cluster were reaching 12GB each, largely due to unoptimized base images and redundant dependencies.
Implementing Lean Infrastructure
To ensure the system was deployment-ready, we implemented a series of optimizations focused on efficiency and reproducibility:
* Transitioned to Minimal CUDA Runtimes: We replaced heavy default images with `nvidia/cuda:11.8.0-runtime-ubuntu20.04`, providing a cleaner foundation for execution.
* Manual PyTorch Installation: By switching to direct `pip` installations for PyTorch 2.1.0, we gained control over the installation footprint and eliminated the unnecessary overhead associated with pre-packaged AI runtime images.
* Removed Conda: Eliminating Conda in favor of streamlined dependency management significantly reduced layer size and environmental complexity.
* Shared Layer Architecture: We engineered centralized CPU and GPU base images. This allows all services to reuse common layers, accelerating build times and drastically reducing total storage requirements.
* Architectural Decoupling: We separated ingestion and upload modules to support edge deployment, ensuring preprocessing occurs as close to the data source as possible.
Measurable Impact
The results of these optimizations transformed the deployment pipeline, creating a leaner and more resilient infrastructure:
* Significant Size Reduction: Individual image sizes dropped from 12GB to 4GB.
* Storage Efficiency: Saved approximately 6–8GB of storage per service.
* Improved Deployment Velocity: Drastically faster image pulls and deployment cycles.
* Reduced Operational Costs: Lowered runtime overhead and storage costs across GPU nodes.
Technical optimization is not solely about model performance; it is about engineering smarter systems. Building lean, deployment-ready AI infrastructure from the start ensures that scaling remains sustainable and cost-effective.